大型节点链接图快速渲染方案
虽然Canvas可以用于渲染万级数据量,但是当节点数超过1w时,尽管一次渲染的时间很短,但还是会产生视觉上的卡顿。为此,我们继续调研了一些优化方案,包括
- 基于Web Worker计算和渲染并行技术【实现并优化】
- 基于Canvas的离屏渲染技术【实现】
- 以及基于Canvas的3D框架—WebGL技术。【未尝试】
1 基于Web Worker的计算与渲染的并行方法
浏览器渲染页面是一个复杂的过程,因为浏览器内核是多线程的,整个过程需要涉及到多个线程,其中最重要的就是JS引擎线程和GUI渲染线程,其中JS引擎线程用来执行脚本文件,依照代码逻辑计算页面元素的位置;而GUI线程则将这些对应的页面元素渲染到页面上。为了防止在渲染过程中因元素的位置发生变化而导致渲染出错,浏览器将GUI渲染线程与JS引擎设置为互斥的关系,即当JS引擎执行时GUI线程会被挂起,GUI更新会被保存在一个队列中等到JS引擎空闲时被执行。在对一个图进行布局的时候,需要多次迭代以至于图中所有节点的位置达到稳定,那么就需要JS引擎线程和GUI线程串行执行,先利用JS引擎线程计算出下一次布局所有元素的位置,然后再利用GUI线程将所有元素渲染至页面上,以此类推,直到所有的迭代都完成。我们猜测这是导致大规模数据在渲染过程中产生卡顿的原因,因为计算节点下一次迭代的过程需要耗时,无法直接进行连续渲染。
Web Worker是一种可为JavaScript创造多线程环境,并将一些高密度计算任务分配给子线程运行的方法,其具体工作流程如下图所示。我们尝试使用Web Worker将可视化工作流并行化来解决渲染卡顿的问题。我们将渲染工作与布局工作分开,具体操作如下:声明一个Worker子线程来执行高时间复杂度的布局迭代计算工作,并将每一次迭代后的计算结果返回给主线程。而主线程通过接收子线程的计算结果,进行每次迭代的布局渲染。
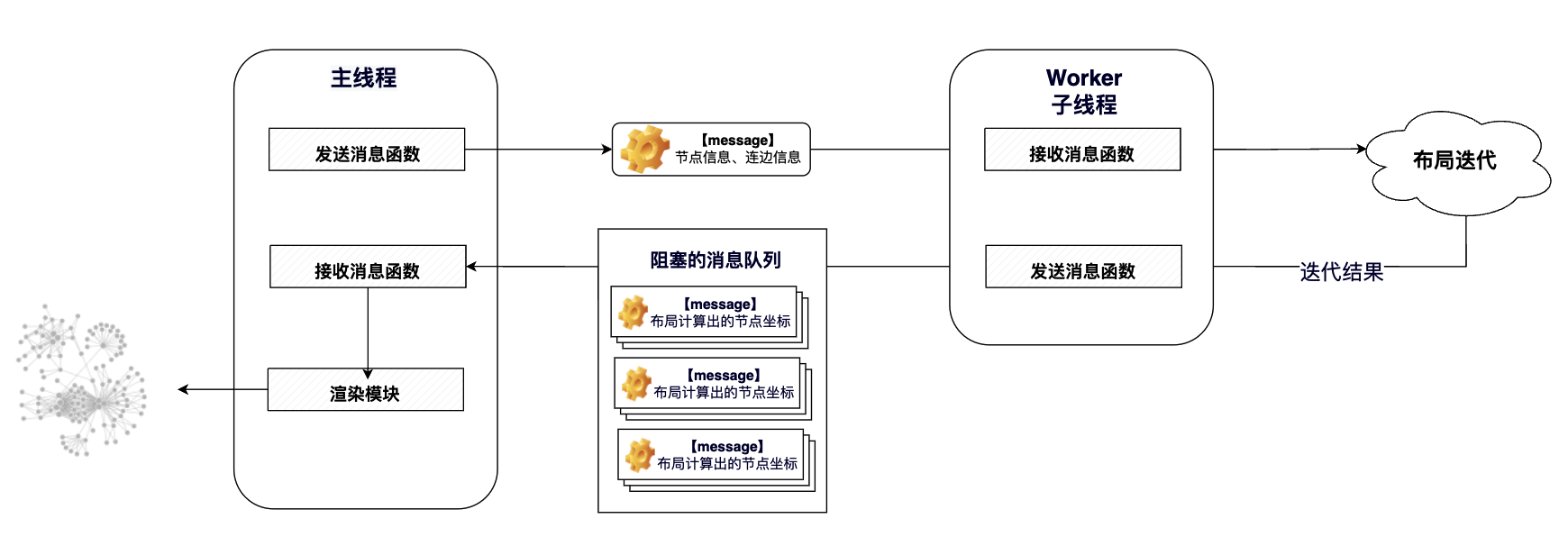
由于布局渲染的方法有两种,分别为基于矢量的SVG布局渲染方法以及基于位图的Canvas布局渲染方法,我同时利用Web Worker进行计算与渲染的并行计算优化,实验Web Worker的有效性。
实验数据规模:
- case1: node(114),link(183)
- case2: node(121),link(334)
- case3: node(207),link(458)
- case4: node(368),link(617)
- case5: node(589),link(1057)
- case6: node(1079),link(2345)
- case7: node(301),link(480)
- case8: node(385),link(144)
- case9: node(429),link(910)
- case10: node(2345),link(5217)
- case11: node(1589),link(5217)
1.1 基于Web Worker计算与渲染并行的SVG布局渲染方法
实验结果:
| 案例 | Case1 | Case2 | Case3 | Case4 | Case5 | Case6 | Case7 |
|---|---|---|---|---|---|---|---|
| 节点数 | 114 | 121 | 207 | 384 | 589 | 1079 | 301 |
| 未使用Web Worker | 1877 | 1705 | 2001 | 2757 | 4934 | 7336 | 2247 |
| 使用Web Worker | 1001 | 2544 | 2460 | 3037 | 5460 | 11509 | 3830 |
| 速度提升(ms) | 87.51% | -32.98% | -18.66% | -9.22% | -9.63% | -36.26% | -41.33% |
| 案例 | Case8 | Case9 | Case10 | Case11 | 3-1(3k) | 1-1(6k) | 6-1(1w) |
| 节点数 | 114 | 429 | 2345 | 1589 | 3228 | 7987 | 18460 |
| 未使用Web Worker | 1869 | 4148 | 16431 | 11954 | 23276 | 50808 | 201359 |
| 使用Web Worker | 2753 | 5344 | 29163 | 20176 | 29797 | 98663 | — |
| 速度提升(ms) | -32.11% | -22.38% | -43.66% | -40.75% | -21.88% | -48.50% | — |
在基于矢量的SVG布局渲染方法的基础上,经过Web Worker计算与渲染并行的优化实验可知,只有在案例1中使用Web Worker的耗时比不使用Web Worker有所提升,但在其他的案例中,通过将计算和渲染分为两个线程反而会造成耗时成本增加。我们分析导致这个问题的原因是:在计算和渲染中,一次渲染的时间远远大于一次布局迭代计算的时间。这样就会出现子线程的布局结果早已计算完毕,但主线程的渲染工作还未完成的情况,消息队列会因此堆积大量子线程发送的布局结果 ,而每次都需要从消息队列中取出数据存在的耗时比在主线程上完成布局迭代计算的时间成本还高。因此,经过实验可知,如果选择SVG作为渲染方法,使用Web Worker无法给用户带来良好的视觉体验。
完整代码见github -> svgWorker
1.2 基于Web Worker计算与渲染并行的Canvas布局渲染方法
当选择使用Canvas作为渲染方法的时候,由于Canvas单次渲染的时间很短,不会出现消息队列大量堆积子线程发送的布局结果。我们猜想,在这种情况下,使用Web Worker对渲染性能的提升是有效的。因此,我们对Canvas开展了计算与渲染并行对实验。具体的实验(数据规模同上)如下表所示:
| 案例 | Case1 | Case2 | Case3 | Case4 | Case5 | Case6 | Case7 |
|---|---|---|---|---|---|---|---|
| 节点数 | 114 | 121 | 207 | 384 | 589 | 1079 | 301 |
| 未使用Web Worker | 56 | 76 | 103 | 169 | 267 | 516 | 160 |
| 使用Web Worker | 121 | 122 | 143 | 256 | 452 | 576 | 213 |
| 速度提升(ms) | -53.72% | -37.70% | -27.97% | -33.98% | -40.9% | -10.4% | -24.88% |
| 案例 | Case8 | Case9 | Case10 | Case11 | 3-1 | 1-1 | 6-1 |
| 节点数 | 114 | 429 | 2345 | 1589 | 3228 | 7987 | 18460 |
| 未使用Web Worker | 88 | 197 | 1333 | 1346 | 1739 | 5120 | 12337 |
| 使用Web Worker | 183 | 244 | 1908 | 1390 | 1755 | 5072 | 13837 |
| 速度提升(ms) | -51.91% | -19.26% | -30.14% | -3.17% | -0.91% | 0.95% | -10.84% |
对比起svg渲染,使用canvas可以明显地提升渲染性能。主要原因是canvas的单词渲染耗时大幅缩短。但是经过多次实验对比,发现在节点数量在超过3k时,会出现明显的卡顿,渲染效果仍并不理想。更糟糕的是,比起不使用Web Worker,使用Web Worker时Canvas的渲染表现反而更差劲了,用户界面仍然存在非常明显的卡顿。
完整代码见 github -> canvas worker
2 优化I/O损耗
在实验过程中我们发现,尽管使用Canvas可以缩短单次渲染的时间,不会出现消息队列大量堆积Worker线程发送的布局结果,但用户界面渲染仍出现较明显的卡顿。经过性能分析,我们发现主要是主线程中的一个数据接收函数占用了大量时间,这个函数在主线程中的作用是接收Worker线程发送过来的数据。当节点数量超过1w时,主线程与Worker线程的数据交换会占用大量时间。因此,需要尽可能缩短主线程与Worker线程的数据交换的时间以达到流畅渲染的目的。
而Worker线程与主线程之间进行数据传递的方式有两种:一种是通过对象拷贝的方式,另一种是通过转移对象引用的所有权的方式。使用对象拷贝的方式,通过内部的克隆算法,将主线程的数据拷贝一份,传给worker。这样worker改变数据并不会影响到主线程。
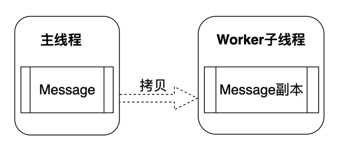
另一种通过转移的方式(Transferrable Objects),不做任何拷贝,而是直接将数据值的引用所有权转移给 worker。如果一个对象的引用所有权被转移,主线程不会再持有该对象的引用,那么该对象在它被发送的上下文中将变得不可用,并且只对它被转移到的Worker线程可用。
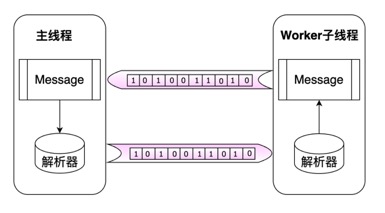
我们实验了这两种数据传递方式的性能指标,发现在单次数据传递的耗时上,使用转移的方式明显优于对象拷贝。下图是在1w节点数据集上,两种数据传递方式的实验结果。


可以看出性能面板上,使用对象拷贝方式一次数据传递的任务耗时107.0ms,而使用传递的方式任务耗时仅有21.2ms。使用转移的方式进行数据传递,要求传递的对象必须为如ArrayBuffer等的指定格式,因此这牺牲了数据的可读性,但能大幅提升数据I/O性能。对此,我们进行了数据I/O的性能实验。我们测试了主线程与Worker线程单次I/O的时间损耗,实验结果如下表所示:
| 案例 | Case1 | Case2 | Case3 | Case4 | Case5 | Case6 | Case7 |
|---|---|---|---|---|---|---|---|
| 节点数 | 114 | 121 | 207 | 384 | 589 | 1079 | 301 |
| 未使用Web Worker | 56 | 76 | 103 | 169 | 267 | 516 | 160 |
| 使用对象拷贝 | 28 | 18 | 22 | 24 | 32 | 32 | 20 |
| 使用Transfer Object | 34 | 26 | 30 | 30 | 43 | 74 | 35 |
| 速度提升(ms) | 17.65% | 30.77% | 26.67% | 20.00% | 25.58% | 56.76% | 42.86% |
| 案例 | Case8 | Case9 | Case10 | Case11 | 3-1 | 1-1 | 6-1 |
| 节点数 | 114 | 429 | 2345 | 1589 | 3228 | 7987 | 18460 |
| 未使用Web Worker | 88 | 197 | 1333 | 1346 | 1739 | 5120 | 12337 |
| 使用对象拷贝 | 21 | 27 | 41 | 47 | 66 | 145 | 452 |
| 使用Transfer Object | 28 | 35 | 117 | 126 | 151 | 483 | 1151 |
| 速度提升(ms) | 25.00% | 22.86% | 64.96% | 62.70% | 56.29% | 69.98% | 60.73% |
对实验结果进行分析,由表可以看出,随着节点数的增加,使用Transferrable Objects的数据传输方式,对数据I/O性能的提升效果显著。当节点数量超过2k时,数据I/O的速度平均能够提升65%。
2.1 将json转为ArrayBuffer处代码实现
只需要将links数据处理并传到worker线程中
//DEFINE IN MAIN |
1.1.3 基于Web Worker+离屏渲染的优化方法—zqc实验【已完成】
在正常的渲染过程中,CPU会将计算好的内容提交到GPU,GPU渲染完成后将渲染结果放入缓冲区,随后显示器会显示缓冲区中的数据。其中GPU屏幕渲染有以下两种方式:
(1)当前屏幕渲染(On-Screen Rendering):指的是GPU的渲染操作作用于当前所显示的屏幕缓冲区;
(2)离屏渲染(Off-Screen Rendering):指的是GPU在当前屏幕缓冲区之外,新开辟一个缓冲区进行渲染操作。渲染的结果不会直接呈现到当前屏幕上,而是等待合适的时机才会显示。相当于在某个时间直接将已经渲染好的图片显示在屏幕上,则不必再执行所有绘图指令。
实现离屏渲染的基本思路,是要将需要重复渲染的图形缓存为图片,在渲染时将图片直接从缓存中读取至另外的画布上。这样做的目的是希望减少在主画布中原生Canvas渲染接口的调用次数,以提升渲染效率。由于在大图可视化任务中,我们需要大量重复地绘制圆点,因此我们尝试将它们缓存为图片,在渲染时直接读取至除主画布外的画布上即可。
由于浏览器的离屏渲染技术是基于Canvas的,所以在这个部分,我们只对Canvas采取离屏渲染优化。大图可视化任务可分为布局与渲染两个子任务,离屏渲染技术只能提升渲染这一子任务的性能,而对布局这一子任务的性能没有任何影响。因此,将离屏渲染应用于大图可视化中具有一项前提条件:计算布局的Worker线程速度快于主线程渲染的速度。
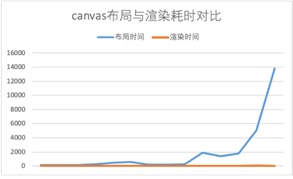
如下图实验结果所示,使用canvas渲染大图的过程中,计算布局的Worker线程的时间开销远远高于主线程渲染。因此在基于Canvas的大图可视化任务中,使用离屏渲染并不会达到提升性能的目的。
完整代码见github -> offscreen